Top 05 Machine Learning Algorithms
Driving with eyes closed, looking into the future, and predicting what is ought to happen, communicating in unknown languages and whispering with lifeless machines are no more a myth, it has turned to be a reality by the possibilities of Machine Learning and Artificial Intelligence.
Data Science the bigger umbrella that spans these emerging technologies have evolved from the capacity of processing Big Data both structured and unstructured and converting it into useful insights and knowledge thereby adding value to an operation or situation.
To be concise, the machine learning task is all about building a model which can perform the task for which it is built, this could be done in four steps – Extraction of data that relate to the business problem or any real-time tasks. Pre-processing of the data and make it compatible with the selected model or tools. Preparation of the model by fitting the data and testing the model for its accuracy. Finally, deployment of the model for the end-users.
Here, the machine learning models are created by using various machine learning algorithms. Most of the beginners in data science and machine learning are facing challenges to choose and apply the appropriate algorithms to build the machine learning models based on the kind of data they have.
Fundamentally, Machine Learning is a way for computer systems to run diverse algorithms without direct human supervision to learn and examine from records. Thus, Machine learning encompass developing models by fitting data to the appropriate algorithms which is selected for learning purpose. If you are a novice, Machine Learning can feel overwhelming – how to pick which algorithms to apply, from seemingly countless alternatives, and how to understand just which one will generate the right predictions that are data outputs. So here we are introducing the top five machine learning algorithms that every beginner in data science should learn and understand.
Linear Regression
Linear Regression is one of the basic and most famous machine learning algorithms used in the field of data science. For every data obtained initially will be viewed as a scattered datapoints on the graph. From that graph by using the linear regression algorithm, it finds a straight line that fits the scattered data points. This line is called best fit line that shows the connections between independent features and a target variable or the numeric result. Also, this line would be able to predict the values. The most popular approach for Linear Regression is the least of squares. The main objective of this approach is to estimate the best fitting line in the way that the vertical distance from every data point of the line is least in the dimension. That is general we could define that the entire aim of linear regression algorithm is to fit a model by limiting separation between the squares.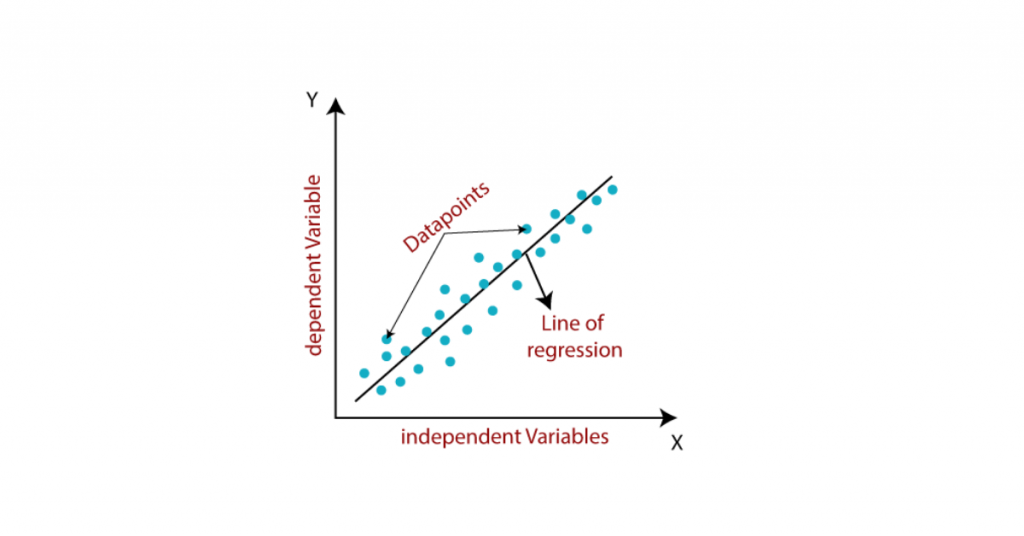
Logistic Regression
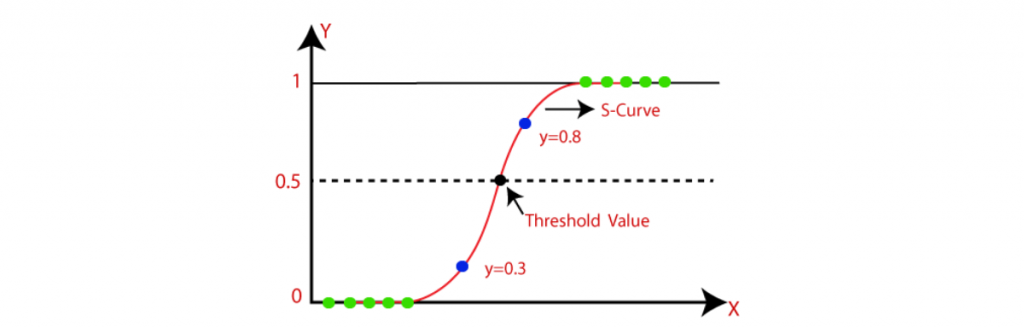
Similar to linear regression, this data science algorithm is used when the output is binary (on the point when the result can best have values). That is, it finds the values for two coefficients that weight each input variable. This is a non-linear S-shaped function called the logistic function g() or Sigmoid function. This feature maps the centre-of-the-road result values to a result with variable Y, which has values extending from 0 to 1. These values can estimate the chance of the occurrence of the variable Y. The characteristics of this S-shaped logistic regression can enhance the calculated relapse for the classification problems. When compared to linear regression, the difference is that this solves problems of binary classification, relying on a logical and non-linear function. Therefore, logical regression determines whether a data instance belongs to one class or another and can also generate the reason behind the prediction, something linear regression cannot do.
Decision Tree
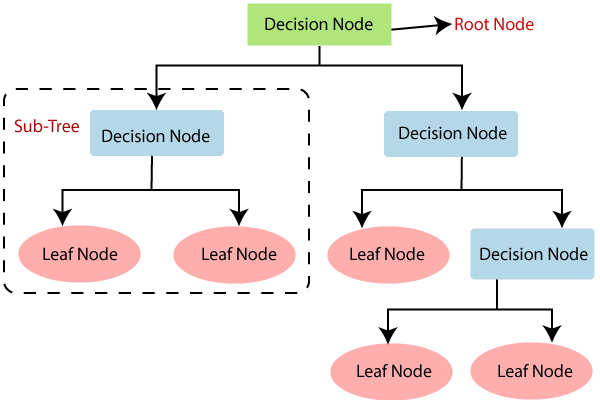
Decision Tree algorithm is a supervised learning technique which can be mainly used for classification problems. But it can be used for solving regression problems too. It is a tree-structured classifier where internal nodes indicate the characteristics of a dataset, branches indicate the decision rules and each leaf node represents the outcome. A decision tree involves two types of nodes, which are the Decision Node and Leaf Node. Decision nodes are used to make the decision and have multiple branches, whereas Leaf nodes are the output of those decisions and do not contain any branches from there. It is a graphical representation for getting all the possible solutions to a problem based on given conditions. It is called a decision tree because, it starts with the root node, and attaches the branches from root and constructs a tree-like structure. To build a tree, we use the CART algorithm, which stands for Classification and Regression Tree algorithm.
Random Forest
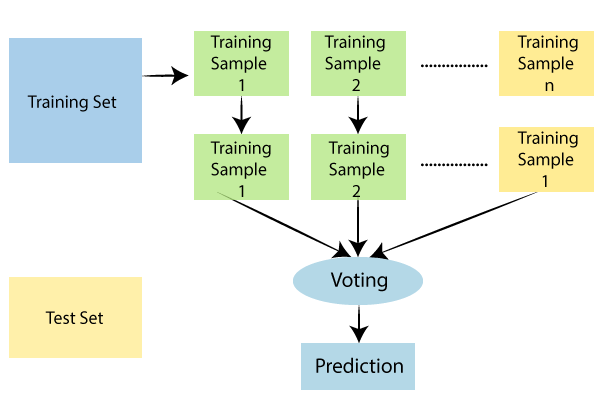
Random Forest is a trending and most popular machine learning algorithm which belongs to the supervised learning technique in machine learning. Random Forest algorithm can be used for both classification and regression tasks in machine learning. It is based on the concept of ensemble learning, which is an algorithm that is of combining multiple classifiers to obtain a solution to the complex tasks and to improve the performance of the model build. As its name says, Random Forest is a classifier which involves a number of decision trees on various subsets of the obtained dataset and takes the average to improve the predictive accuracy. Instead of relying on one decision tree, the random forest takes the prediction from each tree and based on the majority votes of predictions, and it predicts the final output.
K-Nearest Neighbour (KNN)
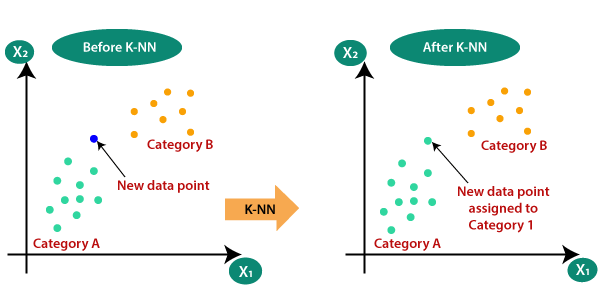
K-Nearest Neighbour algorithm is one of the simplest and common Machine Learning algorithms based on Supervised Learning mechanism. In short K-Nearest Neighbour algorithm can be termed as KNN. It estimates the common identities between new data point and the already available data points. Then insert the new data point into the category that is most similar to the available categories. K-NN algorithm takes all the available data and classifies a new data point based on the similarity relying between the new data point and other data points exist there. This means when new data appears then it can be easily classified into a most similar and suitable category by using the K- Nearest Neighbour algorithm. We can use this KNN algorithm for both Regression and Classification problems, but mostly it is used to solve complex classification tasks to find a solution for it. It is a non-parametric algorithm which is also called a lazy learner algorithm because it does not learn from the training set and instead it stores the dataset and at the time of classification, it performs an action on the dataset.